Chemicals and Apparatus
All reagents and IBF were of analytical grade: chloroform was used as received from Sigma–Aldrich. Stock solutions were prepared by weighing the appropriate amounts of the reagents and dissolving them in chloroform. Working solutions were prepared by diluting stock solutions with chloroform. Serum samples were obtained from fasting and healthy men. It was assumed that the IBF concentration of all these serum samples is zero. Fluorescence spectral measurements were performed on a Perkin-Elmer LS 45 Fluorospectrometer with a 10 mm quartz cuvette at room temperature. The FL WinLab Software (Perkin-Elmer) was applied for measurements spectra recording.
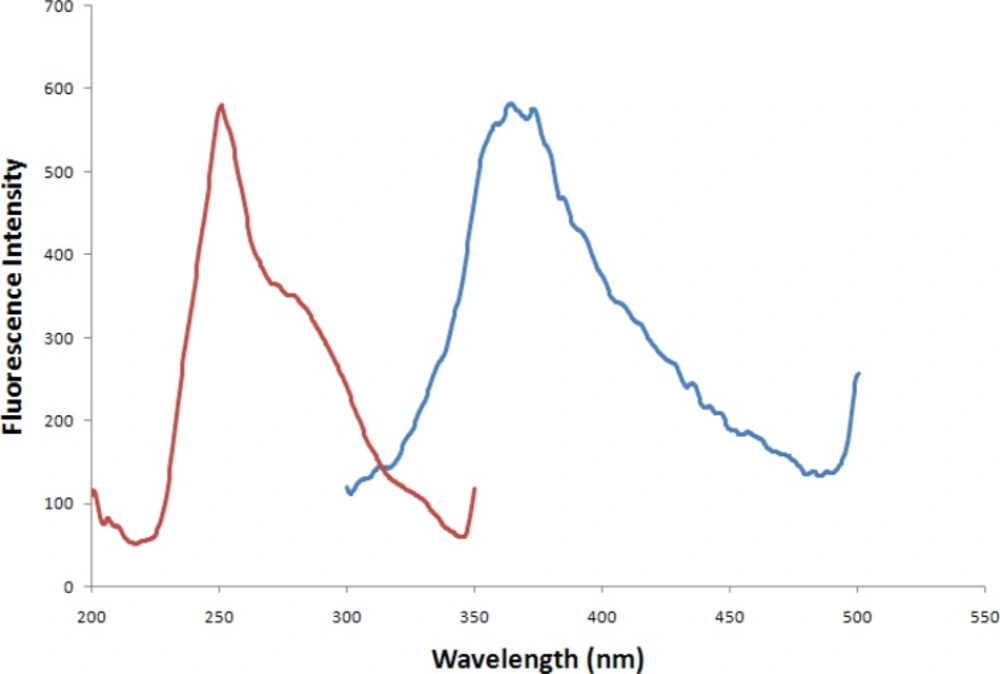
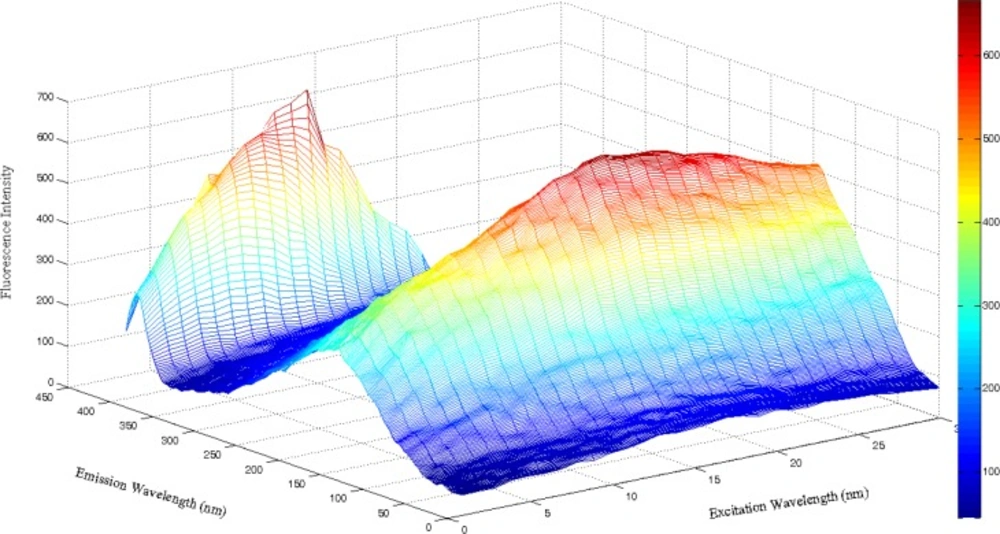
The instrument consists of two monochromators (excitation and emission), a Xenon light source, a range of fixed width selectable slits, selectable filters, attenuators and two photomultiplier tubes as detectors. The spectrofluorimeter is connected to a PC microcomputer via an IEE serial interface. All measurements were performed in 10 mm quartz cells at room temperature. EEMs were registered in the ranges λem = 300–500 nm, each 0.5 nm, and λex = 235–265 nm, each 1 nm for emission and excitation, respectively. The excitation and emission monochromator slit widths were fixed at 10.0 nm both, and the scanning rate was 600 nm min−1.
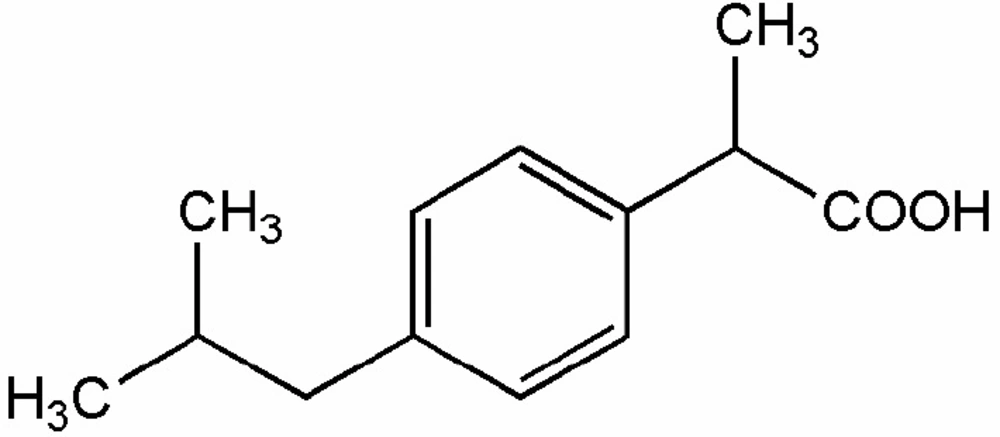
Stock solutions of the analytes (1 × 10-3 M) were prepared by dissolving appropriate amount of IBP in chloroform. Working solutions of lower concentrations were prepared by proper dilution from the stock solution.
Software
All calculations were done using MATLAB 7.1 (
24). Appropriate m-files for employing unfolded principal component analysis combined with artificial neural network (UPCA-ANN) were written by our group. A useful MATLAB toolbox was developed for easy data manipulation and graphics presentation. This toolbox provides a simple mean of loading the data matrices into the MATLAB working space before running UPCA-ANN. It also allows selecting appropriate recording spectral regions, optimizing the number of factors, calculating the analytical figures of merit and plotting emission and excitation spectral profiles and also pseudo-univariate calibration graphs. This MATLAB toolbox is available from the authors on request. Other calculations were performed using routines developed in our laboratory in the MATLAB environment.
Procedure
A 1000 µL mixture of serum and analyte (IBP) was shaked with 2.0 mL of chloroform and 1.0 mL HCl 2M for 5 min and then centrifuged at 7000 rpm for 15 min and procedure was repeated three times. The organic phase was separated and dissolved in 4 mL chloroform and employed for spectroflurometric. The blank solution was prepared using the same procedure as for analytes explained above except that no analyte was added to the serum. All the spectrums were recorded in the excitation range from 235–265 nm (step 2 nm) and in the emission range from 300 to 500 nm (step 0.5 nm). The excitation and emission monochromator slit widths were fixed at 10.0 nm both, and the scanning rate was 600 nm min−1.
Assigning training and test sets
Three sets of standard solutions (
i.e. calibration, prediction and validation sets) were prepared. As shown in
Table 1, the calibration set contained 40 standard solutions, 9 standard solutions as validation set, and 12 solutions were used in the test set. The respective concentration of IBF in the standard solutions was 0.1 × 10
-7 - 47 × 10
-7.
For preparation of each solution, the required volumes of stock solution were added to a 10.0 mL volumetric flask, and the contents of the flask were diluted to volume with chloroform.
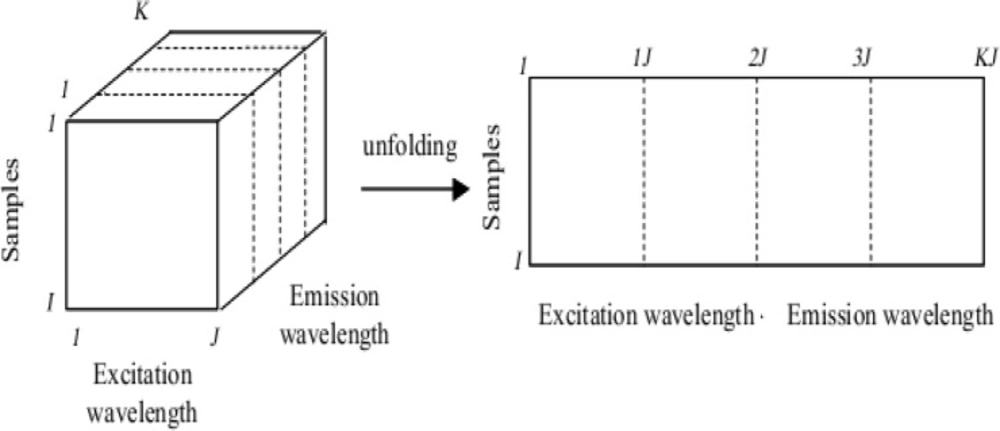
When a sample produces a J × K data matrix (a second-order tensor), such as an EEM (J = number of emission wavelengths, K = number of excitation wavelengths), the corresponding set obtained by ‘stacking’ the matrices obtained for each of I samples is a three-dimensional or three-way array. Appropriate dimensions of such an array are I × J × K (I = number of samples). The resulted 3D array was unfolded to a two way array. This array was used in order to PCA and then resulted scores splitting to training and test sets. In this step around 20% of the samples (12 out of 61) were selected from unfolded matrix as test set (
Table 1) and 15% as validation set (9 out of 61). The best way of assigning test and calibration sets is dividing dataset to guarantee that both sets individually cover the total space occupied by original data set. Ideal splitting of data set is performed in such a way that each of the samples in test set is close to at least one of the samples in the training set. Various methods were used as tools for splitting the whole original data set into the training and test set. According to Tropsha
et al. the best models would be built when Kennard and Stone algorithm was used (
25). For more details see (
26,
27). Thus, this algorithm was applied in this study
Principal Component Analysis (PCA)
Multivariate calibration methods are important applications in multicomponent spectrophotometry. Let A and C represent the matrices of unfolded fluorescence intensities and the concentration of a set of standard solutions containing serum spiked with IBF, respectively. Then, the resulted matrix has l columns, the following Equation applies:
where K is the coefficient matrix. According to this equation, it is possible to determine the principal components individually with the application of suitable chemometric techniques (
29).
PCR is principal component multivariate mathematical tools, which have been successfully applied to analysis of multicomponent mixtures. As with the more conventional classical least squares method, PCR also need a calibration step where chemometrics model is generated on the basis of the measured spectra and relevant component concentrations of the standard samples. Spectra of the unknown solutions are then compared with the calibration set to predict the concentrations of the validation and subsequently the unknown samples.
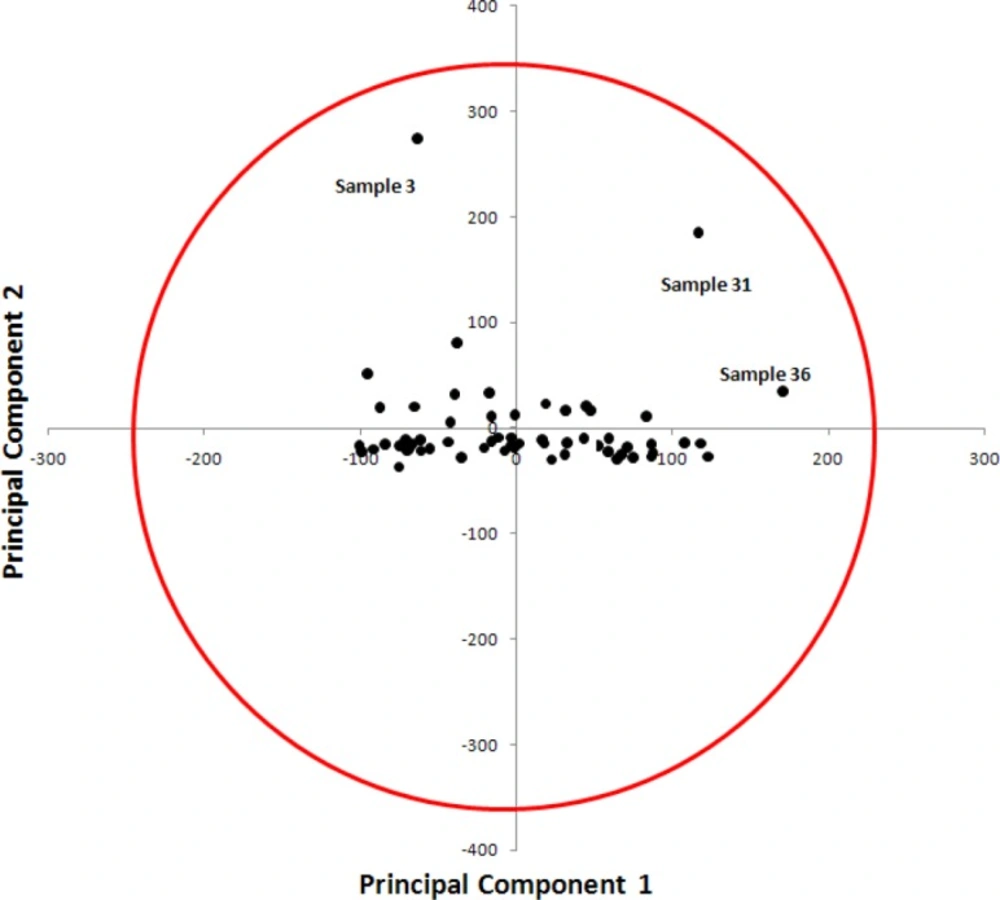
The resulted unfolded matrix was exported to the MATLAB routines for the purpose of PCA. PCA models the maximum directions of variation in a data set by projecting the samples as a swarm of points in a space spanned by PC’s. Each PC is a linear function of a number of original columns of unfolded matrix, resulting in a reduction of the original number of variables. PCs describe, in decreasing order, the most variation among the samples, and because they are calculated to be orthogonal to one another, each PC can be interpreted independently. This allows an overview of the data structure by revealing relationships between the samples as well as the detection of deviating samples. To find these sources of variation, the original data matrix of unfolded EEM, is decomposed into the new spaces such as sample space and the error matrix. The latter represents the variation not explained by the extracted PC’s and is dependent on the problem definition. The approach describing this decomposition is presented as:
A(m,l) = T(m,k)P(k,l)T + E(m,l)
Where A is the unfolded matrix matrix, T is the scores matrix, P is the loadings matrix, E is the error matrix, m is the number of samples, l is the number of columns in original unfolded matrix, and k is the number of PC’s used.
In PCR procedure, all calculated scores were collected in a single data matrix and the best subset of PCs was obtained by a stepwise regression.
Artificial neural network
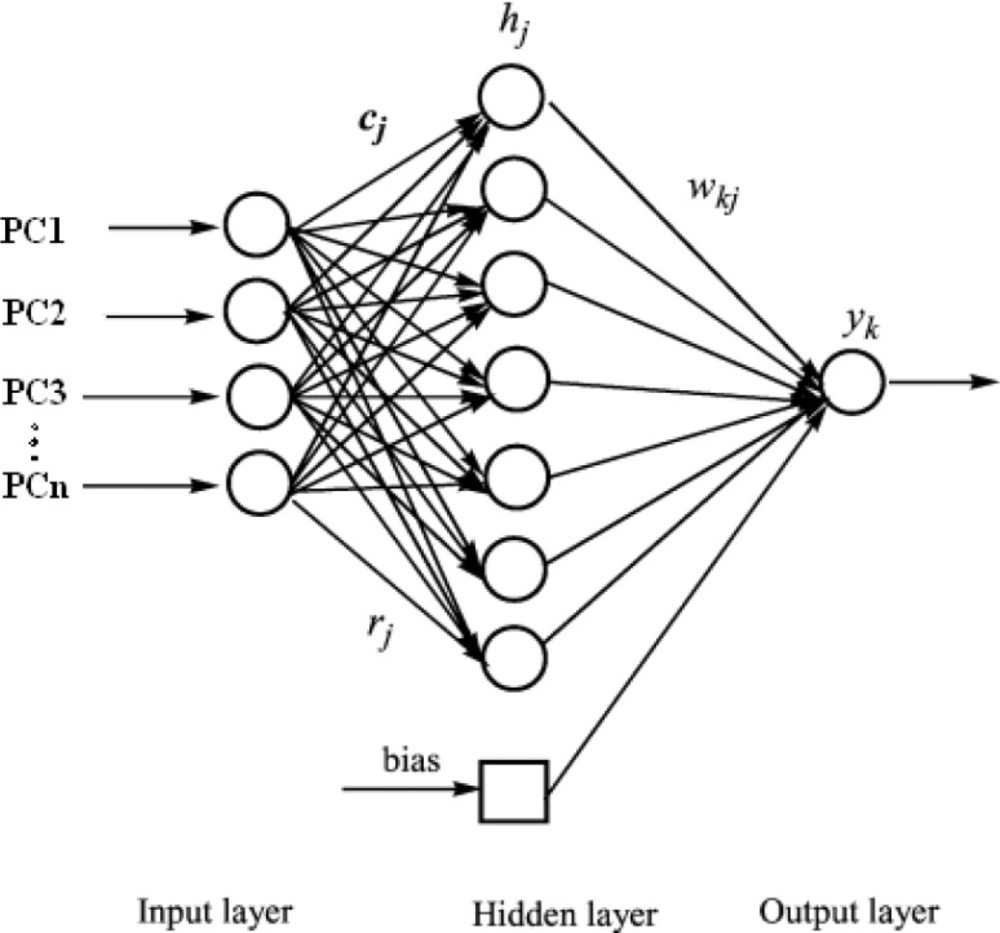
One method to providing a more flexible form of linear regression is to use a feed-forward neural network with error back-propagation learning algorithm. This is a computational system whose design is based on the architecture of biological neural networks and which consists of artificial ‘neurons’ joined so that signals from one neuron can be passed to many others (
Figure 1). Clarification of the theory of the artificial neural networks in details has been adequately described elsewhere (
30) but little relevant remarks is presented. ANN are parallel computational tools consisting of computing units named neurons and connections between neurons named synapses that are arranged in a series of layers.
Back propagation artificial neural network includes three layers. The first layer namely input layer has ni neurons, and the duty of this layer is reception of information (i.e. inputs) and transfers them to all neurons in the next layer called the hidden layer that number of them was indicated by nh. The neurons in the hidden layer calculate a weighted sum of the inputs that is subsequently transformed by a linear or non-linear function. The last layer is the output layer and its neurons handle the output from the network and it is the calculated response vector. Duty of synapses is connection of input layer to hidden layer and hidden layer to output layer. The manner in which each node transforms its input depends on the ″weights″ and bias of the node, which are modifiable. On the other hand the output value of each node depends on both the weight, and biases values. In addition, depend on, the weighted sum of all network inputs, which are normally transformed by a nonlinear or linear transform function determining the outputs of the network.
The relation between response, Yo of the network and a vector input, Xi can be written as following if number of neurons in the output layer is equal to 1 (same with our condition in here):
Where bI is the bias term, WJI is the weight of the connection between the Ith neuron of the input layer and the Jth neuron of the hidden layer, and f is the transformation function of the hidden layer. In the training process, the weights and bias of the network which are the adjustable parameters of the network are determined from a set of objects, known as training set.
Through the training of the network, the connection weights are regulated so that error of calculated responses and observed values were minimized. For this, a nonlinear transfer function makes a connection between the inputs and the outputs. Commonly neural network is adjusted, or trained, so that a particular input leads to a specific target output. There are numerous algorithms available for training ANN models. We used back propagation algorithm here for training of network. In this algorithm several steps for minimizing of networks were performed and the update of weight for the (n + 1) the pattern is given as:
With using following equation the descent down the error surface is calculated (
36):
Where α and μ are momentum and learning rate, respectively.
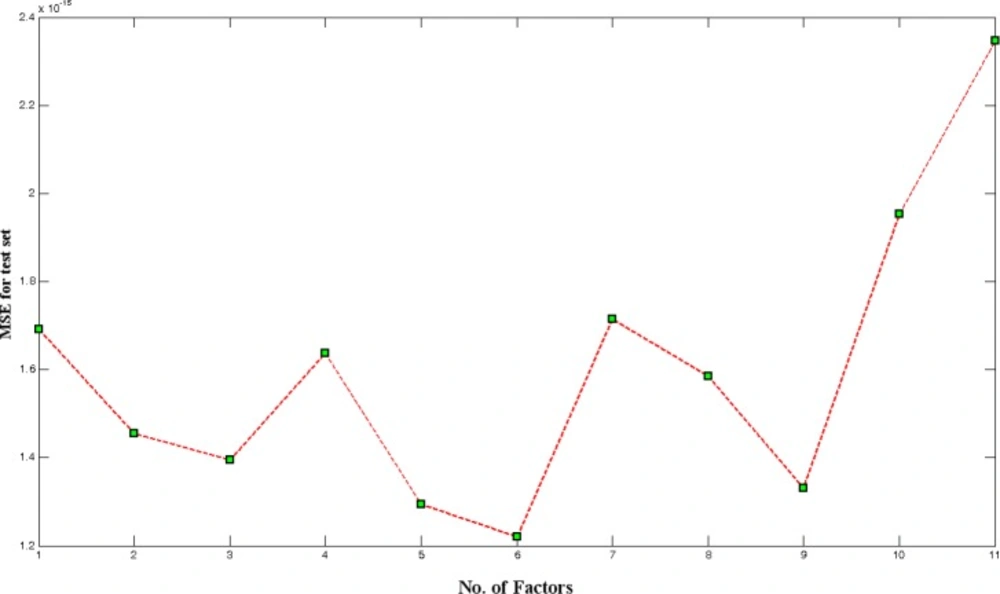
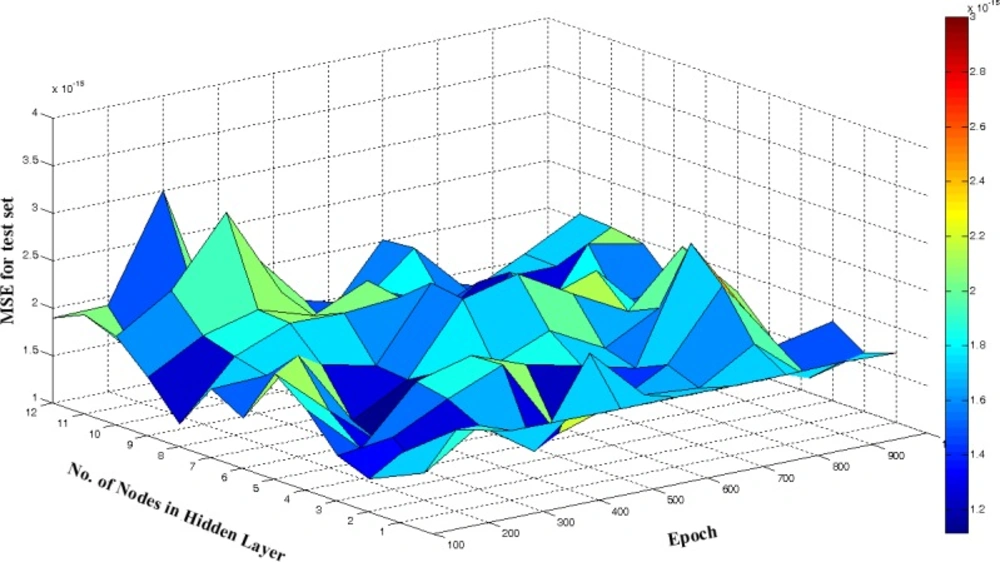
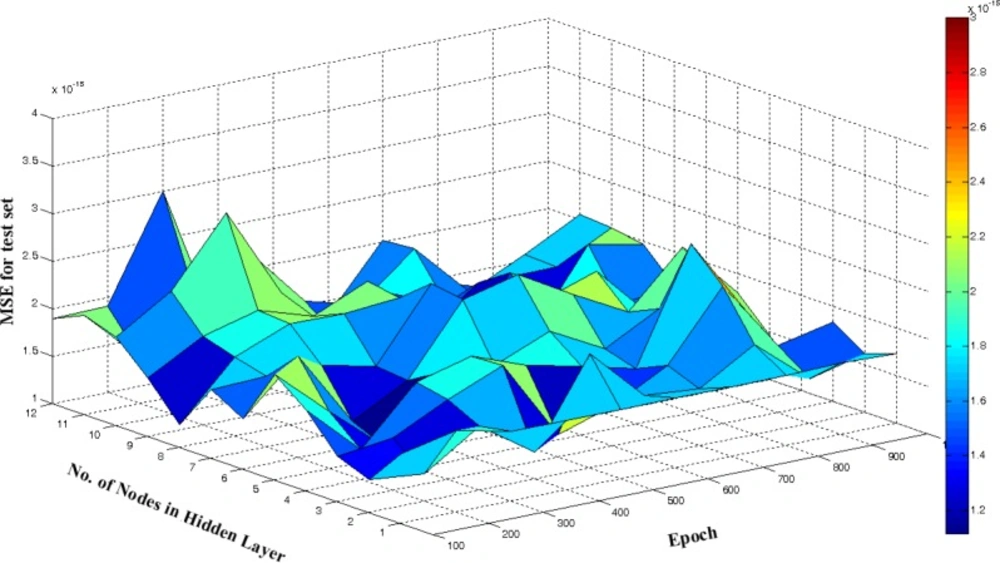
With respect to above demonstration, in the ANN some adjustable parameters exist including number of nodes in input and hidden layers, transfer function of hidden and transfer function output layers, momentum, number of iteration for training of network and learning rate that were evaluated by obtaining those which result in minimum in the error of prediction.
As mentioned above in order to avoid overfitting and underfitting, a validation set was used in the ANN modeling.
All ANN calculations were performed using home-developed scripts using the MATLAB package.
Statistical parameters
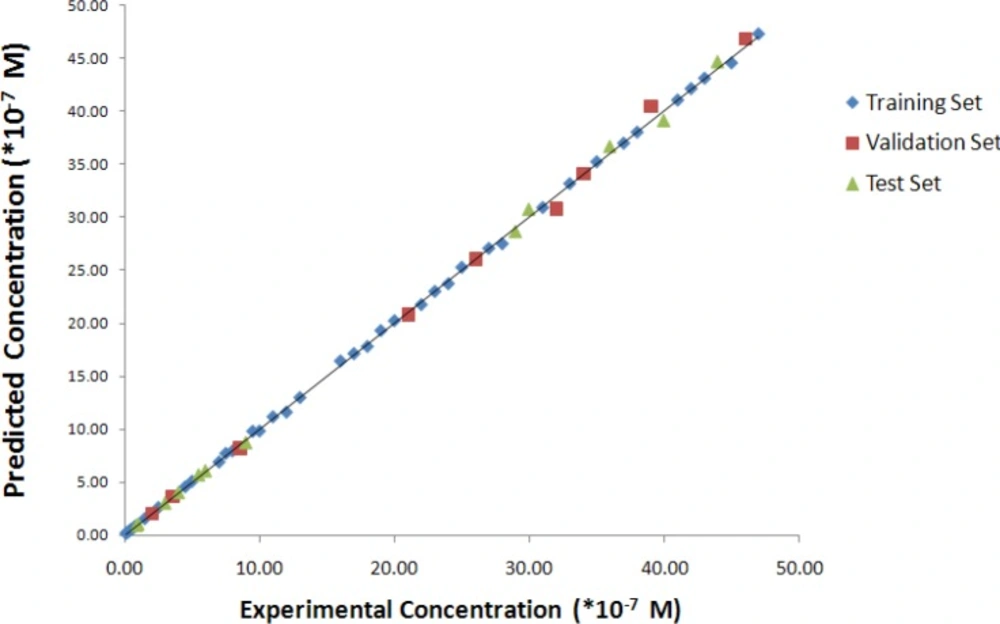
For an evaluation of the predictive power of the generated model, the optimized model was applied for the prediction of the IBP values of the test compounds in the test set, which were not used in the calibration procedure.
For the constructed models, some general statistical parameters were selected to evaluate the prediction ability of the model for IBF concentration. For this case, the predicted IBF concentration of each sample in the prediction step was compared with the experimental IBF concentration (
31-
33).
The root mean square error of prediction (RMSEP) is a measurement of the average difference between predicted and experimental values, at the prediction stage (
33). The RMSEP can be interpreted as the average prediction error, expressed in the same units as the original response values. The RMSEP Was obtained using the following formula:
The second statistical parameter was the relative error of prediction (REP (%)) percent that shows the predictive ability of each component, and is calculated as:
where yi is the experimental concentration of CLX in the sample i, yi represents the predicted CLX concentration in the sample i, y- is the mean of experimental CLX concentration in the prediction set and n is the total number of samples used in the prediction set.
Square of the correlation coefficient (R2) is another parameter that was calculated for each model using following formula:
R2 is a statistic that will give some information about the goodness of fit of a developed model. Saying another way, the R2 is a statistical measure of how well the developed model approximates the real data concentration. An R2 of 1 indicates that the regression line perfectly fits the data.
HPLC procedure
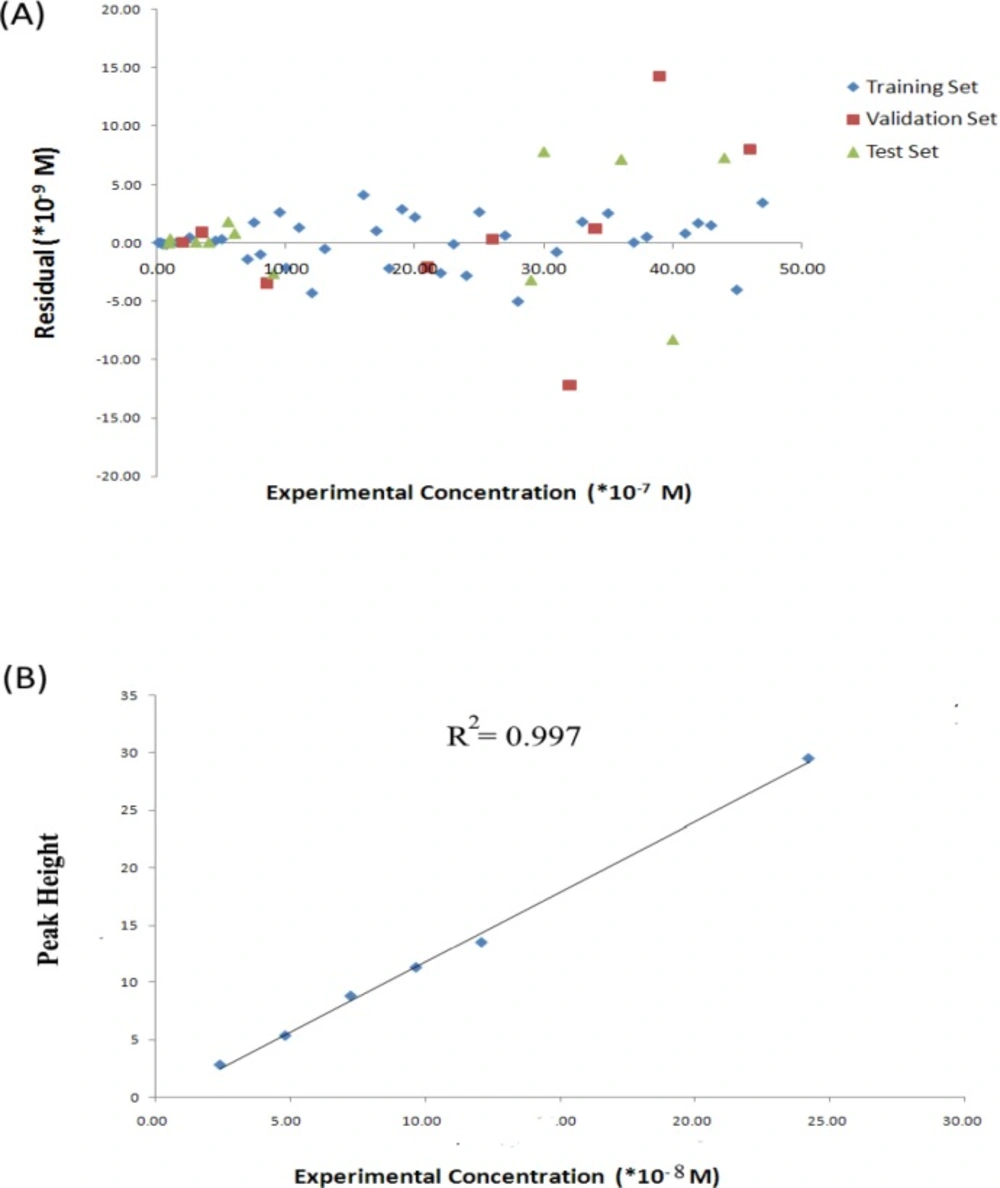
In order to determine the concentration of IBP in human serum using HPLC, an extraction method was used applying hexane. Serum samples were stored at −40 °C until assay and frozen samples were thawed in water at 37 °C. The serum samples were spiked with appropriate amounts of standard solutions, resulting in an IBP concentration range from 2.43 × 10-8 to 2.43 × 10-8 M. Aliquots of blank, calibration standard, or test serum samples (100 μL) were pipetted into separate Eppendorf tubes, containing different concentration of IBP. The samples were extracted with 1 mL of hexane, after vortex mixing for 20 s. the organic phase was separated and its evaporation at 40 °C under the nitrogen flow.
The HPLC system used consisted of two pumps of Shimadzu LC-10A solvent delivery system, a system controller (SCL 10AD), a spectroflurometric detector (RF-551) operated at excitation and emission wavelengths of 267 and 360 nm, respectively. A column oven (CTO-10A), a degasser (DGU-3A) and a data processor (C-R4A) all from Shimadzu, Kyoto, and Japan were applied. The analytical column was a CLC-ODS-3 (MZ, Germany), 125 mm × 4 mm I.D., 5 μm particle size. A mixture of acetonitrile and Triethylamine buffer (47:53) was used as the mobile phase. The column oven temperature was set at 50 °C and the mobile phase was filtered, degassed, and pumped at a flow rate of 1.8 mL/min.
The calibration equation was H = 1.0 × 10 -8c – 0.511 (R2 = 0.997), where H is the analyte height and c its concentration in molar. Calibration curves were obtained by linear least-squares regression analysis plotting of peak-height versus the IBP concentrations. For the analysis of real samples containing IBP, appropriate dilutions were made with mobile phase, before filtering and injecting them into the chromatograph.